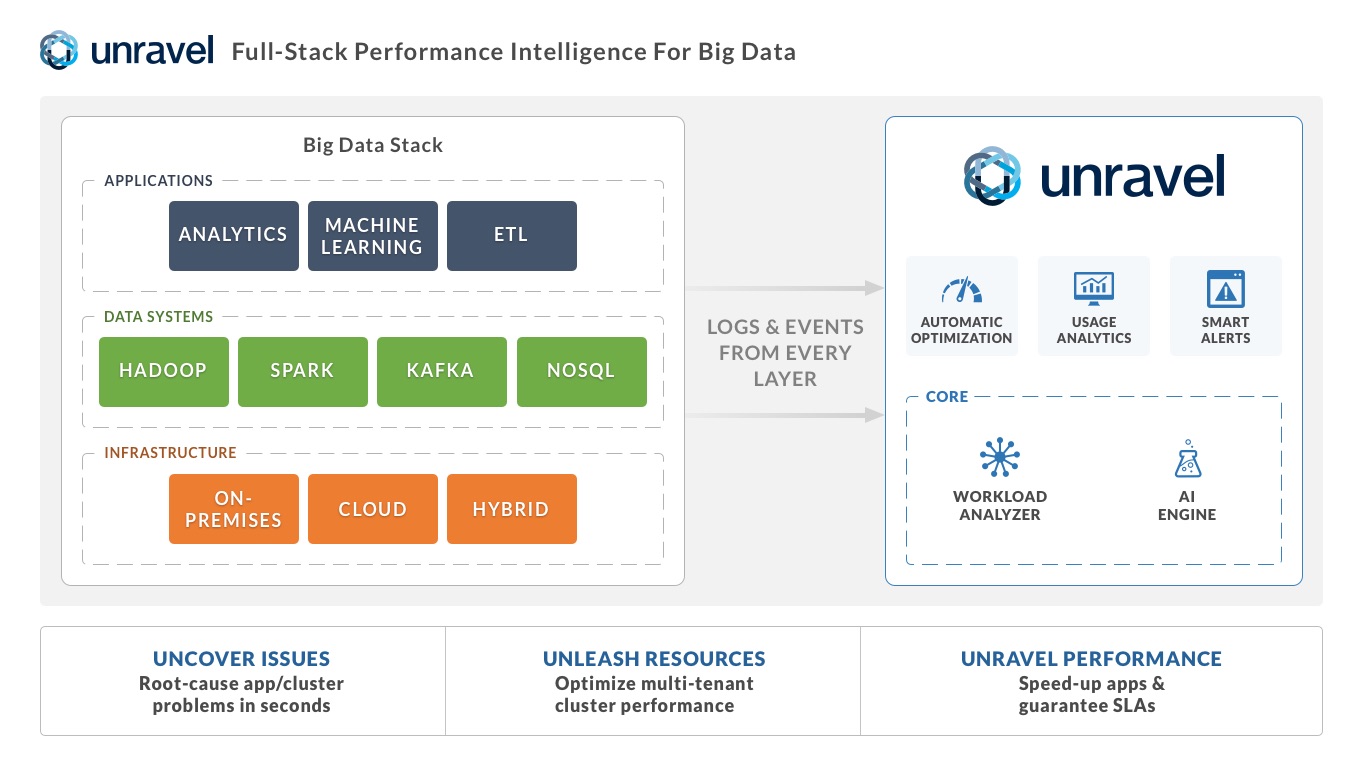
MENLO PARK, CA--(Marketwired - Sep 13, 2016) - Unravel Data, a full-stack performance intelligence platform for optimizing Big Data operations (DataOps), today emerged from stealth with more than $7 million in Series A led by Menlo Ventures, with an additional seed investment from Data Elite Ventures. Unravel Data accelerates all applications in a Big Data stack or cluster, optimizes multi-tenant resource utilization and provides operations intelligence, all from a single platform, delivering the full value of Big Data by resolving complex issues across the stack.
In production with Fortune 100 companies since January 2016, Unravel Data's team of Big Data experts and engineers (from the likes of Cloudera, Oracle, and Microsoft), including founders Kunal Agarwal and Dr. Shivnath Babu, has been working behind the scenes to bring to the expanding Big Data market -- which IDC estimates to be worth $187 billion by 2019 -- a single source of performance and operations intelligence for the entire modern data stack.
With Big Data, Comes Big Complexity
Big Data implementations have become top priority for businesses of all sizes to accelerate revenue, create new products and enable quick decision-making. With this adoption comes increased complexity, which is underlined by an acute shortage of talent capable of running and maintaining these intricate Big Data systems. In fact, Gartner's Nick Heudecker estimates that, "through 2018, 70 percent of Hadoop deployments will fail to meet cost savings and revenue generation objectives due to shortage of skills and integration challenges."1 Businesses are spending too much time solving Big Data operations problems, and productivity is suffering.
Up until now, enterprises have relied on raw logs and basic infrastructure monitoring solutions to keep their Big Data applications and infrastructure optimized. As companies continue to adopt multiple Big Data technologies for their needs, the complexity and time required to diagnose and resolve problems have grown exponentially. The challenge is finding a single full-stack platform that can analyze, optimize, and resolve any challenge that exists with Big Data applications or infrastructure quickly and accurately.
"The rapid adoption of critical distributed technologies such as Hadoop, Spark, and Kafka into the Big Data stack has made the need for Unravel Data even greater," said Dr. Shivnath Babu, Unravel Data Co-Founder and Associate Professor of Computer Science at Duke University. "It's difficult to determine whether an application is not performing at its peak because of bad code, data partitioning, system configuration settings, resource allocation or infrastructure issues. Unravel Data resolves these challenges immediately, thereby eliminating 90 percent of the time previously spent to identify and mitigate complex issues across the stack."
"As Big Data projects move from pilots to production, they encounter serious performance problems that frustrate both data analysts and IT operations," said Venky Ganesan, managing director, Menlo Ventures. "We at Menlo have been looking for a next-generation solution to this problem. Unravel Data had the perfect trifecta of an amazing founding team in Kunal Agarwal and Dr. Shivnath Babu, deep proprietary machine learning algorithms, and world-class customers, including Autodesk and YP.com, in production. We are proud to be the lead backers of this revolutionary product."
Ganesan will join Shivnath Babu and Kunal Agarwal on the Unravel board of directors. Advisors of Unravel include industry veterans such as Tasso Argyros, founder of Aster Data Systems, which was acquired by Teradata for $263 million, Ken Rudin, formerly of Facebook and current Head of Growth and Analytics at Google Search, Bhaskar Ghosh, formerly of LinkedIn and current VP of Engineering, Operations and Security at NerdWallet, Jeff Magnusson, Director of Algorithms Platforms at StitchFix, and Daniel McCaffrey, VP of Data and Analytics at Climate Corp.
"Unravel Data has taken a data science approach to solving the complexity of operating a Big Data stack," says Tasso Argyros. "Unravel's approach of applying machine learning to telemetry data from the entire Big Data stack automatically diagnoses and resolves performance and reliability problems. Unravel Data enables IT to simplify daily operations and see much quicker time to value from Big Data investments."
With the financial support from Menlo Ventures and Data Elite Ventures, along with guidance from a deep bench of industry laureates, Unravel Data is primed to deliver operations, developers, lines of business managers and emerging roles, such as Chief Analytics Officers (CAOs) and Chief Data Officers (CDOs), the performance and operations visibility necessary to effectively and efficiently optimize Big Data applications, all from a single platform.
Key Features
For more information on the Unravel Data platform's key features, please visit: www.unraveldata.com
Availability
Unravel Data is available immediately for on-premises, cloud or hybrid Big Data deployments. Unravel Data currently supports Hadoop, Spark, and Kafka, with plans to add support for other systems such as for data ingestion (Storm, Flume), NoSQL systems (Cassandra, HBase) and MPP systems (Impala, Drill). For more information, please visit www.unraveldata.com.
Supporting Materials
Data Sheet: www.unraveldata.com/datasheet.pdf
Case Studies: www.unraveldata.com/resources
About Unravel
Unravel Data automates and simplifies Big Data operations (DataOps) with a full-stack performance intelligence platform that accelerates application performance, optimizes multi-tenant resource usage, and provides operations intelligence -- all from a single location. Unravel Data supports popular Big Data systems such as Hadoop and Spark for both on-premises and cloud environments. Customers include leading Big Data practitioners such as Autodesk and YP.com. Unravel Data was founded in 2013 by Kunal Agarwal and Dr. Shivnath Babu when they experienced the frustration of manually troubleshooting performance problems in Big Data stacks firsthand. Unravel's founding team includes Big Data experts and practitioners from companies such as Cloudera, Oracle, and Microsoft. Unravel Data has raised a total of $7.2 M in two rounds of funding from Menlo Ventures and Data Elite Ventures.
Copyright Statement
The name Unravel Data is a trademark of Unravel Data™. Other trade names used in this document are the properties of their respective owners.
1 "Predicts 2016: Evolving Information Infrastructure Technologies and Approaches Bring New Challenges," Published: 1 December 2015, Analyst(s): Ted Friedman, Roxane Edjlali, Guido De Simoni, Adam M. Ronthal, Nick Heudecker, Merv Adrian, Bill O'Kane, Mark A. Beyer, Donald Feinberg
Contact Information:
Editorial Contact
Paul Doyle
(617) 733-2173