MENLO PARK, CA--(Marketwired - Mar 8, 2017) - Unravel Data, the industry's only intelligent application performance management (APM) platform designed to simplify DataOps, today unveiled a new set of automated actions for improving Big Data operations and performance. Designed by Unravel after months of working with 100+ enterprise customers and prospects to uncover their biggest Big Data challenges, Unravel 4.0 makes DataOps more proactive and productive by automating problem discovery, root-cause analysis, and resolution across the entire Big Data stack, while improving ROI and time to value of Big Data investments.
DataOps is a set of practices and tools used by Big Data teams to increase velocity, reliability, and quality of data analytics. Done right, DataOps fosters a tight collaboration between data engineers/data scientists and IT operations, which in turn leads to faster time to market with Big Data apps that are high performing and reliable.
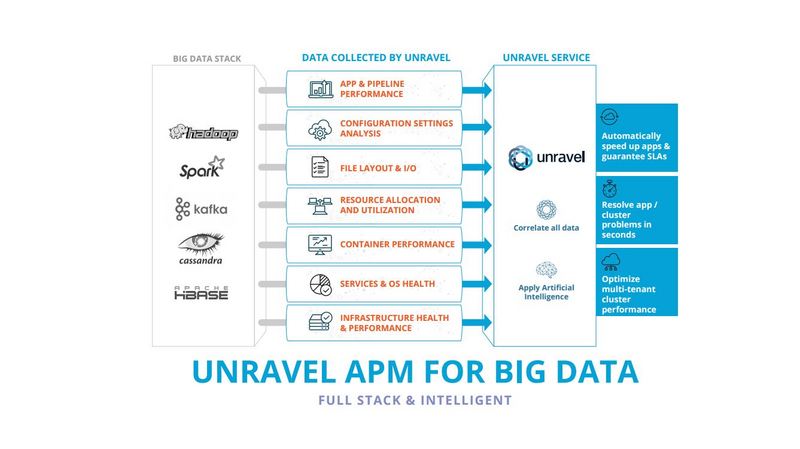
IDC's Worldwide Semiannual Big Data and Analytics Spending Guide predicts that the Big Data and business analytics market will grow to $203 billion by 2020. However, running applications on this mass influx of Big Data systems is not becoming any easier. Operations teams typically leverage multiple tools in order to manage their Big Data stack, such as Application Logs, Cloudera Manager / Ambari UI, MapR Control System, Job History UI, and Spark Web UI. This approach causes bottlenecks and creates delays for users who must turn to short-handed DataOps teams to gain complete diagnostic understanding of the issues, which inevitably results in lost money and time. Unravel mitigates these issues by providing a full-stack performance management software that monitors everything from applications down to infrastructure, all from one place.
"Unravel Data improves the reliability and performance of our Big Data applications and helps us identify bottlenecks and inefficiencies in our Spark, Hadoop, and Oozie workloads," said Charlie Crocker, Director of Product Analytics at Autodesk. "Unravel also helps us understand how resources are being used on the cluster and forecasts our compute requirements, while enabling us to better scale our cloud infrastructure."
These Big Data challenges faced by the likes of Autodesk (and YP.com) present real-roadblocks for enterprise customers aiming to make their Big Data apps production-ready. Unravel 4.0 addresses these challenges and more by providing DataOps with an intelligent and automated full-stack APM platform that enhances Big Data operations, makes applications more reliable, and improves overall cluster utilization -- all from a single, connected screen.
"With 4.0, we're able to address the skills gaps and technical challenges that our Fortune 2000 customers feel by simplifying and automating problem detection, diagnosis and resolution," said Kunal Agarwal, CEO and Co-founder at Unravel Data. "Not only does Unravel simplify DataOps, it helps our customers yield results from their investments by drastically improving the time-to-market for their Big Data apps. Organizations should be able to rely on their Big Data stack. Unravel is instilling the necessary confidence for moving apps from development to production, and guaranteeing that their mission critical apps run fast and error free."
Key features of Unravel 4.0 include:
- Runaway applications - detects and diagnoses apps over-allocating resources or under-utilizing containers; provides context of why and re-allocates optimal resources for these apps
- SLA management - automatically detects and diagnoses why app is slow; recommends ways to speed up application and improve reliability
- Configuration settings - alerts on bad configurations in the cluster; shows all apps that could run better with new settings, and applies new settings on demand
- Service degradation/slow-down - shows which service is degraded, e.g., NameNode, MetaStore; provides context of why and which apps/users are affected; removes apps/users causing the issue
- Storage utilization and caching -- alerts users if storage is reaching capacity; shows which tables and files can be removed or cached to get more mileage out of current storage
"Big Data stacks are becoming increasingly complex, and that complexity seems to grow almost geometrically as new apps are added to the stack," said George Gilbert, Lead Analyst, Big Data and Machine Learning at Wikibon. "In such an environment, running a root cause analysis, as one example, can become unfathomably more challenging and time-intensive. The Unravel platform is built on a recognition of these realities, providing an approach that effectively automates and speeds up problem resolution."
Availability
Unravel 4.0 is available now. Companies such as Autodesk and YP.com are already using Unravel Data to manage their production Big Data systems. Unravel Data is available immediately for on-premises, cloud or hybrid Big Data deployments. Unravel Data currently supports Hadoop, Spark and Kafka, with plans to add support for other systems such as for data ingestion (Storm, Flume), NoSQL systems (Cassandra, HBase) and MPP systems (Impala, Drill). Unravel Data fully supports secure deployments with Kerberos, Apache Sentry, Encryption, etc. For more information and a free trial, please visit http://unraveldata.com/free-trial/.
Additional Information
Data sheet: http://www.unraveldata.com/datasheet.pdf
Case Studies: http://www.unraveldata.com/resources
About Unravel Data
Unravel Data automates and simplifies Big Data operations (DataOps) with a full-stack performance intelligence platform that accelerates application performance, optimizes multi-tenant resource usage, and provides operations intelligence -- all from a single location. Unravel Data supports popular Big Data systems such as Hadoop and Spark for both on-premises and cloud environments. Customers include leading Big Data practitioners such as Autodesk and YP.com. Unravel Data was founded by Kunal Agarwal and Dr. Shivnath Babu when they experienced the frustration of manually troubleshooting performance problems in Big Data stacks firsthand. Unravel's founding team includes Big Data experts from companies such as Cloudera, Oracle, and Microsoft. Unravel Data has raised a total of $7.2 M in two rounds of funding from Menlo Ventures and Data Elite Ventures.
Copyright Statement
The name Unravel Data is a trademark of Unravel Data™. Other trade names used in this document are the properties of their respective owners.
Contact Information:
PR Contact
Paul Doyle
10Fold
(617) 733-2173